Overview of KubeVirt
Why KubeVirt?
As development moves more and more into containerized application stacks in orchestration platforms like Kubernetes, there will continue to be workloads that cannot easily be containerized. KubeVirt was created with these workloads in mind, providing a way to bring virtualized application components into a unified development platform where developers can build, manage, deploy, and scale applications regardless of whether their components are containerized, virtualized, or a mix of the two.
What does KubeVirt do?
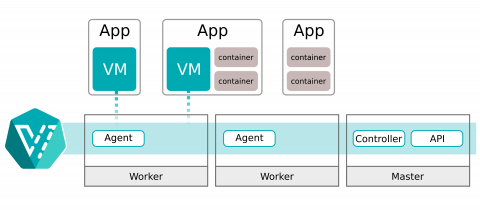
KubeVirt provides additional functionality to a Kubernetes cluster, enabling it to manage virtual machine workloads. This additional functionality can be grouped into three categories:
- Custom Resource Definitions (CRD) - Additional types added to the Kubernetes API to handle Virtual Machines like other Kubernetes objects (such as Pods).
- Controllers - A set of deployments running on the cluster that provide an API endpoint for managing the new KubeVirt CRDs. These usually run on a cluster's control plane nodes.
- Agents - A set of node level DaemonSets to manage node tasks related to virtualization. These usually are configured to run only on a cluster's worker nodes.
How does KubeVirt run virtual machines?
At its heart, a KubeVirt virtual machine is a Pod running a KVM instance in a container. Associated with the Pod is a VirtualMachineInstance, which links the Pod to a VirtualMachine, and provides an endpoint for some advanced operations like migration and disk hotplug operations. At the top level is a VirtualMachine which is the primary resource for interacting with a virtual machine. This structure allows KubeVirt to manage unique VM states like "stopped", "paused", and "running" as well as track and schedule Pods across nodes when performing live migration of VMs from one node to another.